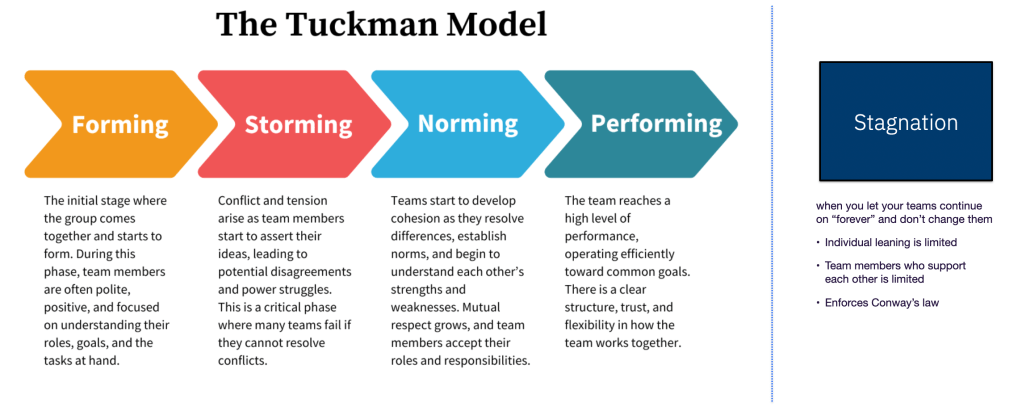
An executive once told me that organization change is a last resort. It is done after you have run out of all other options. Recently I’ve noticed multiple squads reporting to me have become stale. This is a known problem and Agile Alliance has a good article on Dynamic Reteaming as a solution.
The easiest answer is to flatten the squads into one and move people around dynamically. However we need to remember why we created the squads in the first place. It was to give them focus. Now this still can be accomplished but more nuanced.
I recently read Reset by Dan Heath where he discussed the concept of a “Genius Swap.” You ask each member of your team what they love to work on. Then inquire what tasks they would prefer to pay others to accomplish. This week I tried that with my team. It was surprising to see how much overlap existed. People wanted to do less of certain tasks while others wanted to do more of the same tasks. I now have guidance from my team how to reallocate roles and responsibilities.
I plan to do this regularly to dynamically change our squads using a bottom up methodology.
I wanted to do an all hands when I first became a 2nd line manager. My goal was to highlight who I am and any changes. Unfortunately the first thing every new manager changes is nothing. The third thing is be everything. Nevertheless I had nothing to highlight. So I pushed it off and now after 3 months it was time.
The slide deck was the easy part. It follows the typical format of celebrations, HR highlights, culture highlights, and looking ahead. The hard part was food. Food becomes a catalyst for engineers coming together. During Covid we started using GrubHub and just allocated everyone spending limits. Problem was after the call ended so did the conversation.
My team is spread across eight timezones from California to Ireland. So 5 pm in Ireland is 9 am in California. I wanted each team to come into the office, eat, listen, then continue to socialize afterwards. Hallway conversations are a great source of “How can we be better” conversations. So I need to order food to be delivered to 6 lab locations.
The typical playbook for this is to have a local manager organize food. Often it ends up being the local cafeteria catering. To get teams excited to come into the office for food I wanted to give them skin in the game.
In our org channel I asked each group to vote on which place to order delivery from for their location. I just brought up yelp and selected places that had delivery at random. In some locations, no one liked any of the options. An argument started about which pizza place in New York City was better. I didn’t mind this because people were engaged and working towards a single decision. Other places it was an even split and they needed a tie breaker who formerly stayed on the side lines. In one case I was surprised the tie breaker eventually went against her husband who was on the same team.
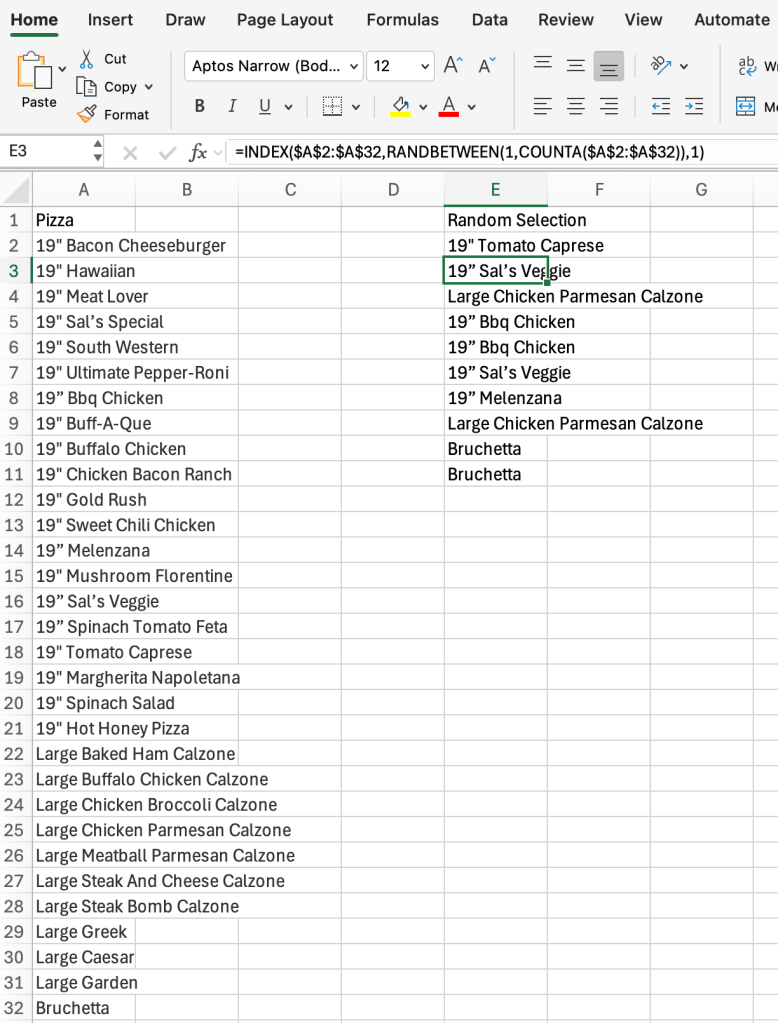
I then started threads on what to order at each restaurant and it was crickets. If I don’t hear back by a certain time, I will put the menu into excel. The function =INDEX($A$2:$A$10,RANDBETWEEN(1,COUNTA($A$2:$A$10)),1) will choose. Every menu has items someone doesn’t want to get. Feedback with suggestions was instant.
So now what went wrong. First I discovered some restaurants will not inform you about delivery limitations. They don’t mention they don’t deliver to a location until you hit “process” on the order. This led to last minute changes in vendor and trying to find equivalent items.
Websites sometimes automatically update the order using the timezone difference between your browser and the restaurant. This is another fun discovery. So you subtract an hour to align with Austin timezone but instead the order is placed 2 hours early.
Not all places deliver breakfast. Also in places like San Francisco traffic is horrid so employees try to come into the office at off times. So for some I just had to order them lunch at a later time.
When I was a child I had some cognitive challenges. My parents moved me to a school which used the Slingerland program. As such I got into the habit of taking notes and repeating information I wanted to remember. I still do that today. I am a big fan of using paper & pen. Yet I am now left with piles of old notes.
Since my wife moved in and the arrival of my two children my notes have moved many times. I have gone from a home office to a man cave, then a man corner, and now a cabinet. We are constantly reclaiming our home from times of yore. So what do I do these notes?
The easy answer is to scan it digitally and put it in an online store somewhere. But that just moves my notes from one cabinet that I ignore to another. So I plan to revisit each note and turn it into a blog post. Not only does that refresh the content in my memory but also shares it with others.
So I took a break from my effort to port Lucene. Late one night I couldn’t figure out how to port logic from Java to Rust. I decided to sleep on it. A few years passed and now I am looking at my code with fresh eyes.
Rather than just pick up where I left off I asked myself what went wrong? Turns out I made a mistake that kills many software projects. I didn’t spend enough time starting the project correctly. The rush to code resulted in spending less time on project setup. I selected a Rust project scaffolding and tried to force a Java project into it. As result one project had to resolve too many problems which resulted in my getting stuck.
Every project needs ADRs
Architecture Decision Records (ADR) allow a team to document why something was done a certain way. Yet more importantly it forces teams to thoroughly explore and agree on decisions. Yes even as a one person team I need to come to the understanding this is the right decision. In this case, I would have discovered that the current project setup was inappropriate. This would have happened while addressing the “Consequences” section of the ADR.
Choosing the right Priorities
I recently read “Decisive” by Chip and Dan Heath. It highlighted the importance of having the right priorities to help resolve conflicts. For instance I wanted the port to have the same features as Lucene. I figured I can reuse Lucene’s unit tests to verify to guarantee that. Well… Lucene is a java library. So I was trying to make Rust behave like Java with JNI in the middle which made life difficult. I was putting a priority on supporting Lucene’s unit tests when it wasn’t always appropriate.
Know the usage
Often when porting code I recall the parable of the blind men and an elephant. I end up spending a good amount of time very focused on a specific part without understanding the big picture. For instance I found myself stuck trying to figure out how to achieve Lucene’s inheritance in a non-object oriented language. I really should have asked how is this part used? If it is used in only one place then inheritance doesn’t matter. I can just combine them.
I try not to enforce Integrated Development Environments (IDE) on my teams. Some developers will give up their religion and home sports team before they drop their preferred IDE. My only ask is the code should build and be understandable outside of their chosen IDE. I often found most IDEs to be more of a hindrance and never to be a one size fits all. As result throughout the day I use multiple IDEs. Anything in Java I will do in Eclipse. I will use Visual Studio Code (vs.code) for tools like watsonx Code Assistant (WCA) in Go, Python, or other scripting languages. I like to use WCA for code comment generation. Yet, for the majority of my coding I use Vim.
Yes that default editor that comes with most Linux, Unix, and Mac distributions. Why… because it is there. My teams need to deliver Software in our SaaS environments and for customers to use on-premises. As I like to work on the front lines I want to use tools that are already there. This is why I don’t use neovim even though it is superior to Vim.
Now I do add plugins to Vim to support color syntax highlighting and autocomplete. So you may be asking why not just use the Vim plugin to vs.code? It is because I need to be used to working in a terminal window. As a developer you should overcome anything hard by doing often. So while I do use a plethora of IDEs, I choose to use the hardest often. That way I can be great at using the terminal editor which is nearly everywhere.
When I was a first line manager with only a handful of employees measuring performance was easy. You can be a “walk around manager” constantly seeing their accomplishments and giving them feedback. Now I am a manager of managers and have far more employees reporting to me. One of my challenges has been how to devote enough time to employees to know them properly. To know how well they are doing and give them feedback. I recently read Decisive: How to Make Better Choices in Life and Work by Chip & Dan Heath. An example from the book was Van Halen.
When the band toured the technical requirements of their shows were immeasurable. So they added contract riders with heavy consequences. Most notably, their riders specified that a bowl of M&M’s candies was to be placed in their dressing room. Separately, in a different area of the contract, all of the brown M&M’s were to be removed. This sounds absurd. Yet, it quickly became an indicator. This showed that the electrical, structural, security, and safety requirements in the contract had been thoroughly observed.
So how do we apply this developers, testers, or even managers? I really don’t like performance metrics tied to code written, test performed, defects found, or projects accomplished. I found those metrics are too easily gained and reinforce the wrong behaviors. Luckily, the company I work for has a list of behaviors they want to see in employees. An example is “work across other teams to improve your solution.” These behaviors are not directly related to performance of source code or quality of the product. Just like the M&Ms it can be an indicator of an ask of the business that is missed.
I rank all employees based on these behaviors. I then ask what the top employees are doing that the bottom are not? The answer to that question then gives me new metrics to drive improvements to performance. Yes this sounds like a moving target and transparency is key. Managers can now have a conversation with employees who are low performers like:
“We have noticed that the top performers in the organization have participated in knowledge shares. What can you share with the greater team?”
The goal of this exercise is to constantly find ways to improve the organization’s performance. It is not meant to find ways to remove low performers. You don’t drown by falling into the water. You drown by staying there.
When Git first came out I was using ClearCase, CVS, and SVN in my day to day development. I thought Git was interesting because the Linux Kernel community embraced it and Linus Torvalds created it. Unfortunately I found It limited and frankly not seamless. Later I worked on the first release of Rational Team Concert which I preferred to Git which was still limited. Then something interesting happened. Git started to get good. In fact it was getting really good. So much so when I later moved to the Watson group in IBM we moved to Git.
It was just simple and easy. We simplified our development process to make the most of its simplicity. I put my head down. I stopped paying attention to Git. I just focused on developing software with what I knew. During that time Git didn’t stand still. It was improving.
I now feel like I am having a Git renascence. I am discovering that I can do things in Git. Earlier, I thought I needed extra tools for these tasks. For instance I thought I needed plugins in my IDE to work on multiple branches at the same time. As I have been slowly breaking my reliance on IDEs I found git worktree.
With Git’s worktree command lets you easily work on multiple branches at the same time. It does so via different directories. This avoids having to stash changes and current work is visible via the directory structure.
To get started
Create a project directory
Clone a bare repository git clone --bare <repo url>.
Go to that new git directory
Now you can add additional parent directories that represent a branch git worktree add --track -b <branch> ../<branch> <remote>/<branch>
Now when you look at the parent project directory, you can work with multiple branches simultaneously. You do this by using the different sub-directories.
Git has come a long way. The more I explore the more I realize the less tools I need. Using less tools means I go faster.
Every year or so I hire new members to my team. As a hiring manager, normally during the interview I don’t ask too many technical questions. That is usually for a follow-up technical interview. Still, I do want to know two things. Does the candidate show knowledge of what they put on their resume? How does the employee handle a technical question they don’t know the answer to? The 2nd part is frankly the more interesting question.
Does the candidate have a network of experts they can pull from? Do they know how to engage open source communities? Are they comfortable jumping into unfamiliar code to understand how it works? I want to hear war stories to better understand how they deal with ambiguity of something new. In the last few years especially from college hires I started getting “I would google it” as an answer. Now that isn’t a horrible answer but you can’t google everything. For instance, Internal projects/services/components will not be answerable via google. Also the answers you find might
This year, I have noticed an increasing number of references to using ChatGPT or Microsoft CoPilot. Often as the first reference used to a problem which has left me with mixed feelings. On one hand, these are wonderful tools. I use IBM watsonx Code Assistant (WCA) at work all the time. I encourage my entire team to use WCA. They should at least use it for generating comments for the code they have written.
Now It can’t be the only tool in your tool chest. It will not have all the answers. This is due to the same reasons I mentioned that Google will not have all the answers. Also some tools like Microsoft CoPilot are still in litigation on the legality of their product. This is fine for working on a school programming assignment but a significant risk to authoring commercial software.
In closing, the best thing for a candidate is to show a breadth of tools & resources to get the job done.
Back in 1999, I took my first steps on Clark University with the intention of majoring in Computer Science and obtaining an MBA. The great thing about College is sometimes you decide to go in a different direction in life. I think it was the space shuttle Challenger case study which turned me off of business. So I focused on Computer Science being my future. Little did I know life would bring me back to business as a career.
I followed a typical technical path of developer, senior developer, and eventually software architect. I have mixed feelings about that last title as I was more playing the role of technical and team lead than pure head in the clouds modeling. Then something odd happened on the way to the airport.
After finally making my way though Logan Airport security I looked at my phone to see slack messages with “congratulations” and “look forward to working under your leadership.” I messaged my manager at the time asking if I missed anything and I got the response “he didn’t tell you.” A few phone calls later I learned that my 2nd line made me a manager.
Now training followed which was provided by IBM. However most of my training came with experience afterwards. Wow, did I get experience. I have had to work with everything from employee love triangles to international espionage. Of course it is nothing I can share which is the hardest part of being a manager. My personal belief is transparency leads to trust and as a manager you can’t always be transparent.
I think of myself as a technical manager as I am still an individual contributor. However as I have increased my number of reports and teams that report to me that has become harder. I am still a believer of leading from the front and getting your hands dirty. Using a combination of tech focal or team lead, setting expectations, and knowing when to write code or jump on a call with a customer helps bring my life/manager/contributor into balance.
I once said as an architect all I could do was document what should be done now as a manager I have people to make it happen. That is still mostly true with the exceptions of matrix employees. Employees love to tell you about their current projects. As a manager you can take that insight and make business decisions around that. However when their day to day doesn’t align with your mission business decisions then your role can feel diminished. Nevertheless over the years I’ve found matrix employees is fine and healthy as long as they are in the same org and have an aligned mission. I guess Conway’s law is alive and well.
I really do enjoy being a manager. As an agile developer I am a firm believer in the Agile Manifesto‘s “Individuals and interactions over processes and tools.”However I never got to truly focus on the “Individuals and interactions” until I became a manager.
I am a big fan of Hot Sauce. Every time my in-laws visit from Belize I ask them to bring Marie Sharps hot sauce. Yes it is spicy but it also has so much flavor. Recently I tried to make my own hot sauce based on a recipe from Joshua Weissman. It was good and tasted a little bit like Franks RedHot. I tried it a few more times with each being a new rift on the recipe. Here is my current recipe for my Garlic Hot Sauce.
Ingredients:
Mix of Peppers. (1 – 1.5 lbs)
3-5 tablespoons of salt.
Water
1/2 to 3/4 cup of Canola or Avocado oil
1/2 cup of distilled vinegar
1-2 head of garlic
For the peppers I started off with mostly tabasco, cayenne, and jalapeño peppers I grew in my garden. All red in color.
However since then I have changed the mix to be more green than red. My current mix is poblano, green jalapeño, and red fresno. Different peppers bring different flavors and I find a mix is good.
Steps
Separate half of the peppers out and place on a baking pan.
Place the baking pan under the broiler. Turn the peppers every so often so they get roasted on all sides. Then let cool.
De-stem peppers, slice lengthwise, and then place in a jar. Please use protection. I like to remove the seeds but it isn’t necessary.
Add a salt/water mix to the jar until full. The mix should be about 4-5% salt by weight.
Let sit for about 2 weeks. I don’t recommend the 3 year required for a Tabasco sauce. You will see it turn white and bubble. That is OK. However do let it air out from time to time otherwise it will explode you on. You are making hot pepper sauce not hot pepper spray.
Peel and slice 1-2 head soft garlic depending on the size of your garlic heads and how much garlic flavor you want added.
Cook the garlic on low heat in the oil until lightly golden brown and let cool and separate garlic from oil.
Separate peppers from brine.
Combine peppers & garlic in blender and blend until completely smooth.
Add oil, vinegar and 4 tablespoons of brine to the blender.